
Same regression, four languages: Rust, Python, JavaScript, R on Australian car prices
Most language benchmarks are comparing ecosystems while pretending to compare languages. They tell you whether pandas is faster than dplyr, whether ml-matrix is faster than nalgebra, whether one set of bindings into BLAS is tighter than another. None of those answers is about the language; the language sits underneath, mostly invisible. Comparing pandas to dplyr is the data-science equivalent of comparing two index funds: you learn about their managers, not their alphas.
I wanted what was underneath. So I took the Australian Vehicle Prices dataset and ported a single ~80-line numerical core to all four of Rust, Python, JavaScript, and R, with the same algorithm, the same PRNG, the same matrix operations, and the same JSON output. Then I timed it, and weighed it.
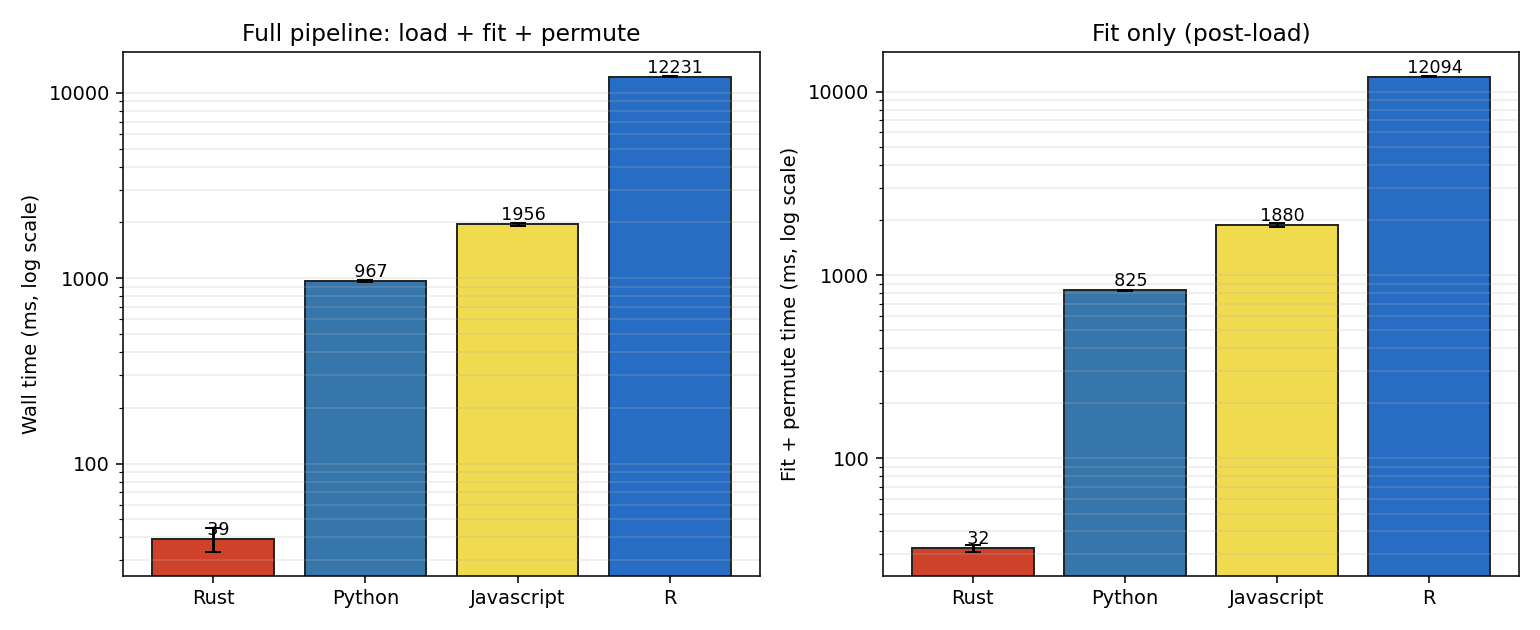
Headline numbers: the four implementations agreed on the regression to within 1e-10, the Rust-to-R wall-clock spread was about 310×, and the JavaScript-to-R memory spread was about 2.5× with V8, of all runtimes, the loser. The first two were expected, the third less so.
The shared task
The data is 16,734 listings of Australian car ads scraped in 2023, nineteen columns wide. After the cleaning pass, that is, dropping missing values, parsing dirty strings like "4 cyl, 2.2 L" and "8.7 L / 100 km" into floats, and killing "POA" and "-" cells, what remains is 14,283 rows by 29 numeric features: seven of them numeric, and twenty-two of them one-hot dummies for body type, fuel, drive, transmission, and used-versus-new. The target is log(price).
The pipeline each language runs is six steps:
- Read the cleaned CSV.
- Split 80/20 train/test deterministically, using a Fisher-Yates shuffle seeded with
0x9E3779B9, the golden-ratio constant lifted from xorshift literature so all four languages agree on the split. - Fit ordinary least squares.
- Score on test, R².
- Compute permutation importance, that is, for each predictor, shuffle that column of the test set thirty times, recompute predictions, and measure the mean drop in R². The bigger the drop, the more the model leaned on that feature.
- Print the result as JSON.
Linear algebra and a shuffle loop. No regularisation, no cross-validation, no library-specific feature_importances_ oracle.
A nod to Rosetta Code
The closed-form OLS solve is a classic on Rosetta Code's Multiple regression task, which spells out the same recipe in thirty-plus languages including all four of mine. This post is essentially Rosetta Code with a permutation-importance loop bolted on, and the harness running /usr/bin/time -v.
There is one departure from how Rosetta is usually written. Rosetta shows each language in its idiomatic form, every implementation playing to its language's strengths. I went the other way: same algorithm, same control flow, same shape, in all four. That includes the hand-rolled xorshift32 and the hand-rolled Fisher-Yates, so the train/test split, and every permutation index, is bit-identical across runtimes.
This matters because the standard objection to "Rust beat R" benchmarks is that they compare a compiled language at full sprint to an interpreted one in slippers. By forcing the same shape into every language, the sweet-spot defence is gone. What remains is the language tax.
The finding: Year is the king
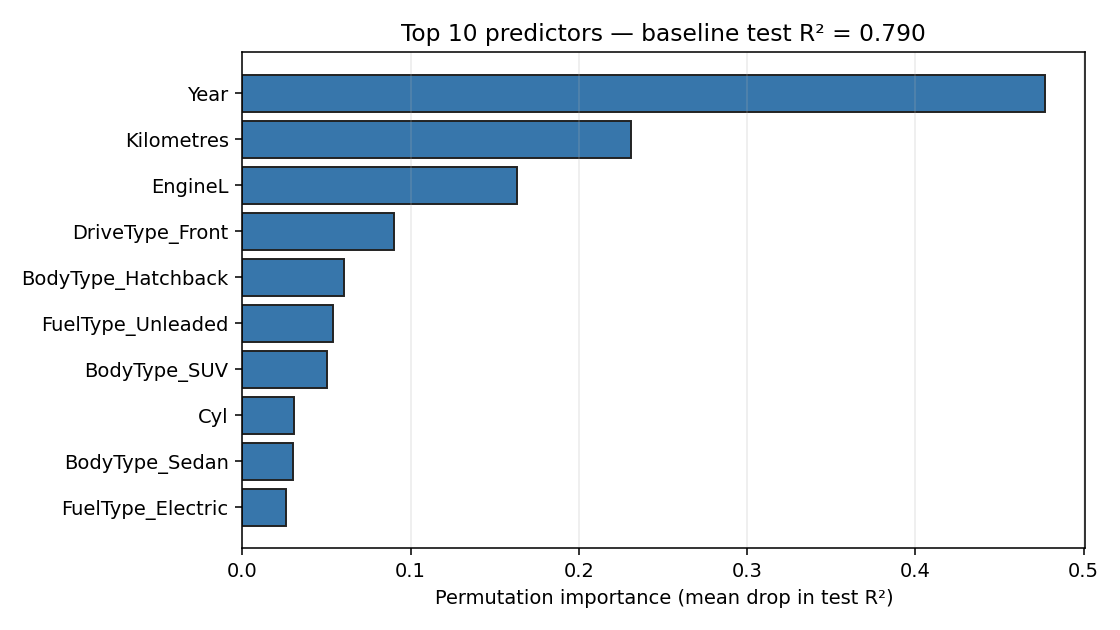
Permuting Year collapses test R² from 0.79 to 0.31, which is roughly half the model's predictive power on a single column. Mileage is second at about half that, engine size third, and after those three the field opens out into body-type and drive-type dummies, each contributing single-digit percent.
A car's price is mostly how new it is, then how much it has been driven, then how big its engine is. Anyone who has sold a car already knew this; the value of the exercise is the convergence of four runtimes onto the same answer, not the answer itself.
Time
Ten timed reps per language after a warm-up. Wall time and peak resident set size both via /usr/bin/time -v.
| Language | Full pipeline (ms) | Fit + permute (ms) | Peak RSS (MiB) |
|---|---|---|---|
| Rust | 39.0 ± 5.7 | 32.4 ± 1.5 | 18.5 |
| Python | 967.0 ± 14.9 | 825.3 ± 5.5 | 47.9 |
| JavaScript | 1,956.0 ± 42.2 | 1,879.8 ± 41.2 | 240.6 |
| R | 12,231.0 ± 96.1 | 12,094.2 ± 93.5 | 95.9 |
Rust is fastest because the small-matrix solve runs in-process, with no BLAS overhead, the inner loop is monomorphised and inlined, and there is no garbage collector. About 40 ms in total, most of which is process startup and CSV parsing rather than arithmetic. Build time is excluded; cargo build --release takes about 7.5 seconds from scratch, 2.6 seconds for an incremental rebuild after a one-line change, and effectively zero on a no-op, paid once per binary and amortised across every run thereafter.
Python with NumPy lands at roughly 25× slower than Rust. The solve itself is fast, since BLAS handles a 30×30 system in microseconds; the damage is done in the permutation-importance loop, which runs 870 times in pure Python, and crosses the Python-to-C boundary several times per iteration. Reaching for sklearn.inspection.permutation_importance, which keeps the loop inside C, would close the gap to roughly four or five times.
JavaScript is roughly 50× slower than Rust. ml-matrix is pure JS, no BLAS underneath, so the matrix multiplications inside the permutation loop run in V8 itself. A typed-array hand-rolled solver would shrink the gap dramatically; I wanted the idiomatic library, for fairness, not the fastest possible thing.
R is roughly 310× slower than Rust. The matrix arithmetic itself is fine, since crossprod and qr.solve are BLAS-backed; the damage comes from the per-iteration overhead of the Fisher-Yates loop in interpreted R, plus the chunked unsigned-32 simulation, both running scalar code in a runtime built for vectorised operations. Vectorising the permutation step would help substantially, but only by abandoning the parallel structure that makes the cross-language comparison fair.
R's number is the most honest illustration of what idiomatic loops cost in a vectorised language. Idiomatic R is lm() and caret::varImp(), which would have brought the gap into Python territory; non-idiomatic R, scalar-loop R, R asked to do per-element work it was never optimised for, is what scalar prices look like.
Memory: V8's tax
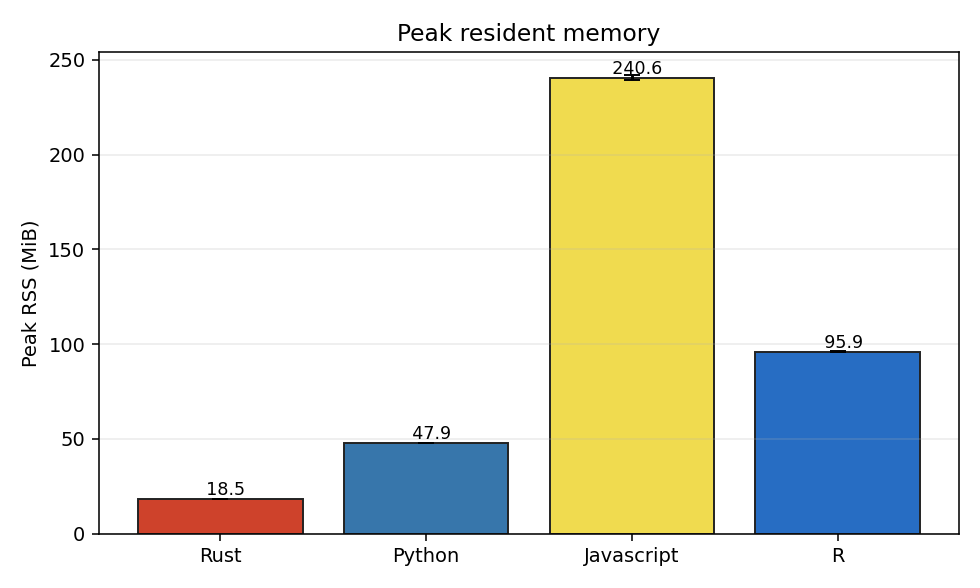
The headline performance number is "Rust beats R by 310×". The headline memory number is the opposite: V8 sits at 240 MiB, R at 96, Python at 48, Rust at 19. JavaScript, the language people reach for when they want their numerical code to run quickly in a browser, uses two and a half times more memory than R does for the same 14k-row regression, and twelve times more than Rust.
V8 is heavily engineered for performance, and the cost is paid in heap. The 240 MiB number is almost entirely V8 itself, not data: ml-matrix's intermediate matrices for the permutation loop are tens of MiB at most, and the input dataset is about 4 MiB. The rest is interpreter overhead, hidden classes, inline caches, and garbage-collector bookkeeping. R, with its much-maligned vector-as-everything memory model, holds the same data in less than half the space. The reputational geography of these two languages is approximately backwards on this axis.
The performance-vs-memory trade is conventionally drawn as a triangle: pick speed, low memory, or expressiveness, and you give up the third. JavaScript, on this workload, breaks the rule the wrong way, neither the slowest nor the smallest, but by a wide margin the heaviest. Rust gets all three corners. R gets one. Python gets two.
A note on what this measures
A head-to-head on language-level performance for a small numerical workload, with all four implementations doing the same operations in the same order on the same bytes, is not a verdict on these languages for actual data work. R was built for interactive statistical exploration, and lm() plus summary() would have given you the regression in two lines and a millisecond; Python with scikit-learn would close most of the gap; JavaScript would be much faster with WebAssembly numerics. The point of the equivalent-code constraint is to isolate the language as the variable, not to recommend Rust for your next regression.
What is left, once the controls are clamped down, is two findings. First, that four very different runtimes agreed on a numerical answer to 1e-10, just by sharing a PRNG and a control flow, is a small advertisement for the Rosetta Code spirit, and a quiet reassurance that numerical code is more language-independent than its loud champions usually let on. Second, that V8's memory footprint, on a workload that ought to be V8's wheelhouse, is the surprise of the table, larger than any other runtime in this comparison, including the interpreted-statistics environment that everyone tells you is the memory hog.
Methodology footnote
- Toolchains: rustc 1.94.1 (release, LTO, opt-level 3), Python 3.12, R 4.3.3, Node 25.2.
- Pre-clean: a one-time Python script parses the raw CSV into a numeric matrix; all four languages then read the same
clean.csv. The "full pipeline" timing therefore includes CSV-of-floats parsing but not the messy-string parsing. - Build time excluded for Rust:
cargo build --releasetakes 7.5 s cold (deps + crate), 2.6 s for an incremental rebuild after a one-line change, and effectively zero on a no-op. - One warm-up plus ten timed reps per language; values reported as mean ± standard deviation.
- Wall time and peak RSS captured via
/usr/bin/time -v; internal timings via each language's monotonic clock. - Source:
~/proj/lang-bench/{python,r,rust,js}/main.*. Verification harness:verify.py. Benchmark harness:bench.py. Charts:charts.py.