
The Black Wall
Your first.
Recall when you were enchanted by their hair, or the tinkle of their laugh, or even just a smirk in your direction was enough to send your heart soaring? Were these moments punctuated by the choice of the next best token you could predict?
At the gumball core of the problem, large language models struggle to hold in their machine minds a concept of reality, a world model, and text is a sparse and incomplete stand-in for the profundity of the world. The juicy core of the problem lies in the fact that frontier models use a hodge-podge of error terms to reduce the distance between the prediction and reality in physics, maths, and almost every field.
Frontier models nowadays are limited by the expansiveness of their memory, and the spontaneity of their input, like brains in boxes, they struggle to comprehend the outside world without a vessel to experience it in. To understand when we will breach that AGI barrier, we have to know whether these models can absorb the full expressiveness of being, and express itself in a way an AI is not yet apt to do.
In so much of our history, we have been influenced by the overwhelming presence of death on our doorsteps, by the crushing inevitability of the lonely passing to the other side. Should frontier models understand the experience of living, the fullness of information we receive, so will they move from the brain in a box to the absorption of the abundance of life.
Yann LeCun, Meta's Chief AI Scientist for 12 years, states this plainly as day, that fundamentally, the entire AI industry is pouring money, billions on billions of dollars, into a dead end system, and that if the goal is AGI, that LLMs are a dead end. His company, Advanced Machine Intelligence Labs, is attempting to build an efficient and accurate world model, and in trying to solve the most fundamental issue, that of the grounding of data and prediction in the real world.
How do people move? How was evolution able to solve the difficult problem of motor sensitivity, and be so generous as to allow us the skill of creativity and free thought? And crucially, how do our brains run on mere watts of power, barely able to power even the tiniest lightbulb?
"The path to superintelligence via LLMs is complete bullshit. It's just never going to work." - Yann Lecun
Scaling Large Language Models past their breaking point, improving and engineering memory and context, these are all secondary to the most fundamental issue of free-thinking, and what amounts to the ability to generalise from the overflow of data in the real world, to concepts and abstract ideas in the mind.
The Joint Embedding Predictive Architecture
LeCun suggests that the path to a true superintelligence is through grounding the model in reality, such that the model predicts the future directly through pixels, in an embedded space. Instead of a language-first model, LeWorldModel and other related JEPA models predict the next embedding which represents a latent state of the world, and compares that embedding to the next. This stands stark against the classic large-language model transformer, which consists of an encoder and decoder, and prediction components in between.
The thesis he proffers is that large language models presents a separation point, wherein we can be distracted by the next-token prediction possibilities of LLMs, but fail to grasp that they do not fundamentally understand reality. LeCun argues that there is no underlying reasoning occurring in each token prediction in those multi-trillion and quadrillion parameter models, only the best prediction of the result. The difference is that you can only cover reasoning deficiencies through further obtained training data, but it cannot synthesise or generate new kinds of data, regardless of how much coaxing you provide it.
LLMs are composed of a simple tokeniser, which is used in a causal inference prediction through a lot of linear algebra, to predict the next token, which is de-tokenised. A standard LLM predicts the next token in a text, with a loss function driven by the reconstruction error in the token stream input. There is no temporal linkage, wherein LLMs sequence order is symbolic and discrete, whereas JEPA is grounded in the evolution of world states.
Autoencoder are the most similar in design to JEPA models, being that they reduce the dimensionality of the data, by reducing the data to a latent space, before decoding. The reconstruction error is often referred to here, which is the difference between the beginning and end result, as well as regularisation.
However, JEPA refuses to be an autoencoder, and drops the entire decoder. It takes the data at the next point in time instead, and calculates the error in embedding space.
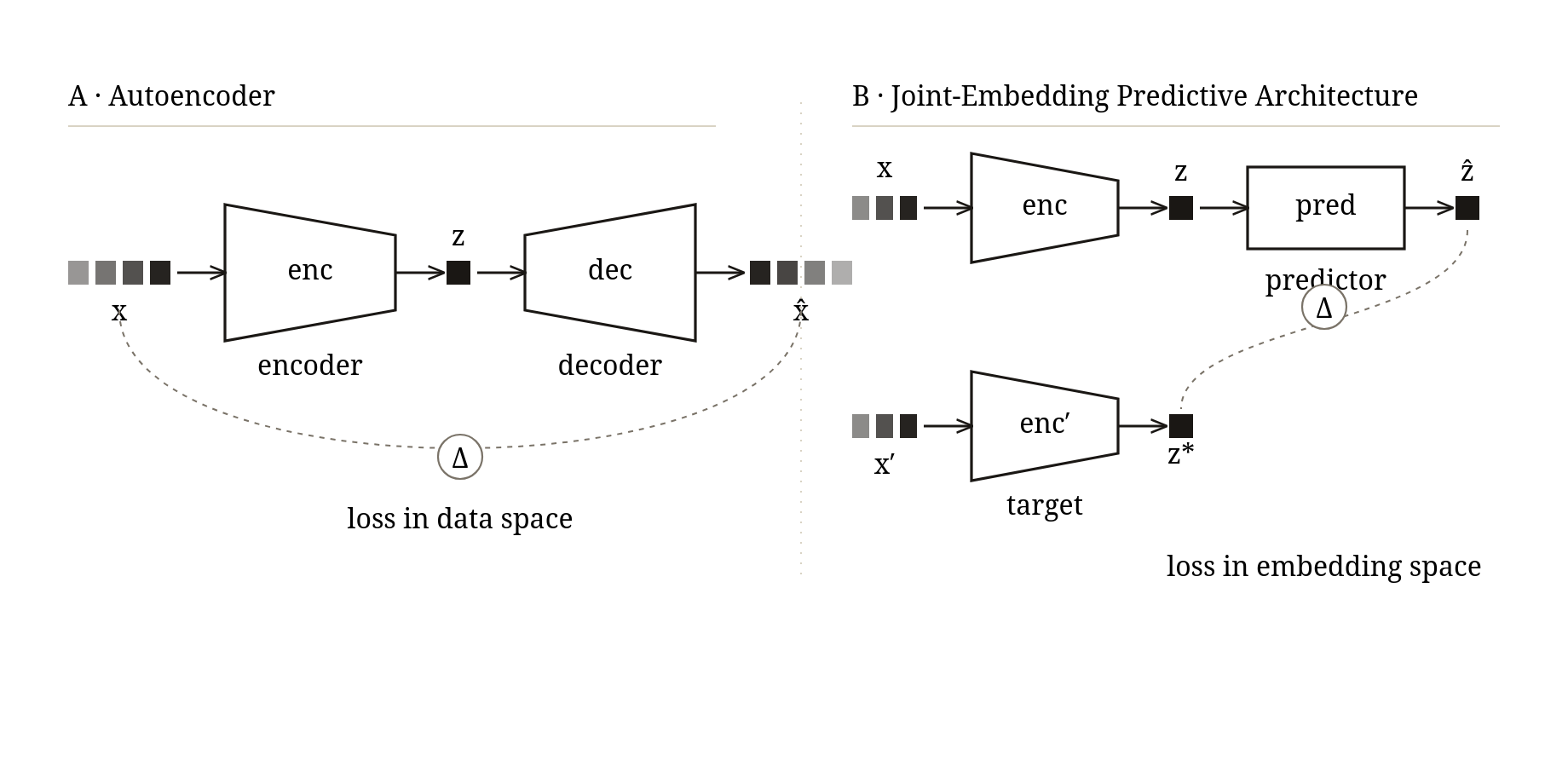
JEPA models, instead, uses a encoder and generator component, with no decoder required or specified. By encoding the data into a latent space and then generating the next step, and comparing that to the result of the next encoding, we effectively imply time continuity. In LeWorldModel, the paper in March 2026, the data is a pixel stream.
The Markov decision process is the problem which the JEPA problem seems to want to solve, which is by improving the planning processes by predicting the next step. This is because it takes an action and a state, which is the classical Markov problem formulation.
Why LeWorldModel?
LeWorldModel takes a stream of "frames" of reality, a set of images, and tries to predict the underlying changing world state, rather than current state-of-the-art methods which aim to predict pixel by pixel changes. A man walking down the street need only think about his destination than the act of walking, yet he accomplishes both. It is only natural to have the core flow and meaning down, and just to let the body do the walking.
Predictions in the embedding space is where the logic lies, wherein the world dynamics are stripped down from the fundamentals, and synthesis occurs. Pixel space, token space, these embedding spaces miss something that is so crucial everyday that we don't even see it. Token space, the space taken up by Large Language Models, is a misdirection, and gobbles up hundreds of watts, and GPU-hours of compute, just to barely reach the intelligence of the average human. Scale cannot be the issue, the hardware needs to change.
If his theory is correct, then Large Language Models are effective, but are more of a distraction from the core underlying physics and reasoning problem which still plagues the LLM community, wherein novel reasoning is an open unsolved problem.
He hypothesises that in 6 months time, everyone will be talking about world models. Frontier models will go and research will go on, but I believe that the gold mine that is JEPA will have its first gold rush in only a few months time.
Let us embrace JEPA.
Appendix: Local LeWorldModel Replication
We replicate LeWorldModel (Maes et al., 2026) end-to-end on a single NVIDIA GeForce RTX 3060 Ti (8 GB VRAM), following the official code at github.com/lucas-maes/le-wm. All architectural and loss-side hyperparameters match the reference, with encoder (ViT-Tiny, 12 layers, dim 192, patch 14), AdaLN-Zero predictor (6 layers, 16 heads, dim_head 64), BatchNorm projectors of width 2048, the Fourier-integral form of the SIGReg statistic (17 knots on [0, 3], 1024 random projections), λ=0.09, AdamW (5e-5, wd 1e-3), bf16, 100 epochs at effective batch 128, linear warmup + cosine decay, gradient clip 1.0, ImageNet image normalisation, z-scored actions, and a 90/10 train/val split (seed 3072).
We show the paper is easily replicable with 3pp of the headline results.
Training curves
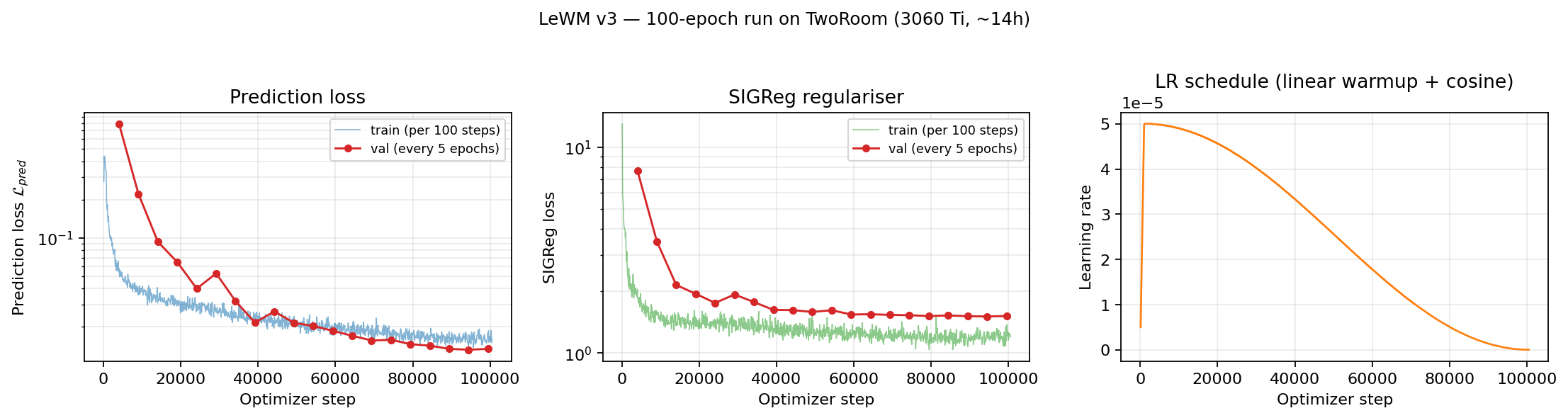
The two-term loss exhibits the dynamics described in §4.3 of the paper: SIGReg drops sharply from ~13 to ~1.7 in the first five epochs, then plateaus, while the prediction loss decreases steadily throughout. The validation curves track training tightly once BatchNorm running statistics have caught up around epoch 15. Very positive results.
Gradient stability
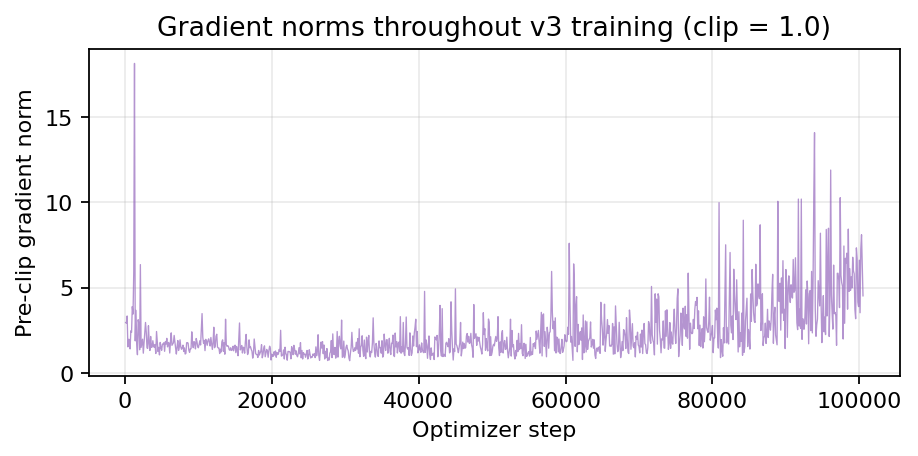
Median pre-clip gradient norm is 1.77 and the maximum observed across all 100,500 optimiser steps is 18.14, comfortably above the clip threshold of 1.0. There are never anywhere near the explosions that occur if SIGReg is replaced with its closed-form (standardised) Epps–Pulley variant which tends to collapse the encoder and drive the gradient to 10⁴ within ~8000 steps. The integrated form of SIGReg penalises both moment mismatches and shape, whereas the closed form pre-standardises the projections and only penalises shape, freeing the encoder to collapse. This is as predicted per literature
Results
| Metric | This work | Paper (Fig. 6) |
|---|---|---|
| CEM success rate on Two-Room (50 episodes, goal offset 25, budget 50, n_iters 30) | 84% | 87% |
| Mean final distance to goal | 0.077 | — |
| Linear probe R² (x, y) | 0.873, 0.674 | (TwoRoom probe in supplementary, not in v1 arXiv) |
| 1-step predictor MSE on fresh rollouts | 0.068 | — |
Six of the eight failed episodes finished within 0.04 of the 0.07 success threshold, so the gap to the paper's 87% is dominated by near-misses rather than catastrophic planning failures. Remaining principled deviations: we use our own Two-Room re-implementation and a random-policy offline dataset (rather than the canonical quentinll/lewm-tworooms HuggingFace dataset), AdamW betas (0.9, 0.95) instead of the default (0.9, 0.999), and a fixed success radius of 0.07 instead of the environment's built-in goal callback.
Total wall-clock for one full pipeline (train + probe + CEM eval at 50 episodes) was 15 h 12 min on a single 3060 Ti.